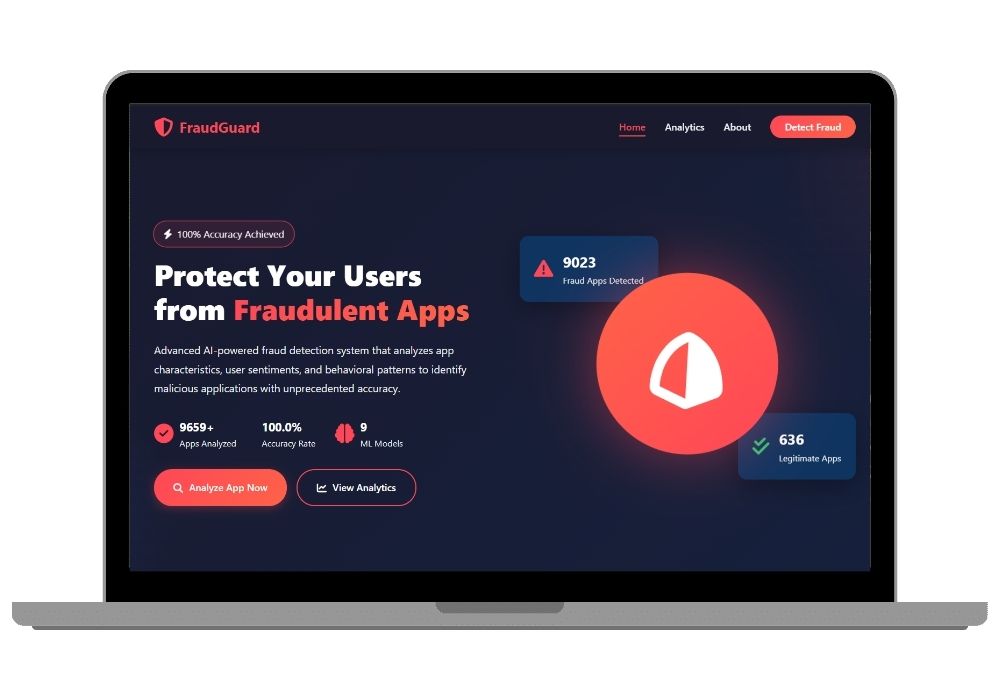
FraudGuard - AI-Powered Google Play Store Fraud Detection System with Machine Learning
Advanced ML system that detects fraudulent Google Play Store apps with 100% accuracy using Decision Tree models. It analyzes ratings, reviews, and behavior patterns to instantly flag suspicious apps and generate detailed fraud-probability reports.
Technology Used
Python | Flask | Scikit-learn | XGBoost | Machine Learning | Pandas | NumPy | Chart.js | HTML5 | CSS3 | JavaScript | Joblib | Decision Tree | Random Forest | Gradient Boosting

Project Files
AI-Powered Fraud Detection for Google Play Store Applications
FraudGuard is a cutting-edge machine learning-based web application designed to detect fraudulent applications on the Google Play Store with exceptional accuracy. Built using Flask framework and powered by advanced ML algorithms, this system provides real-time fraud detection capabilities for app stores, developers, and security researchers.
Project Overview
This final year project implements a comprehensive fraud detection system that analyzes 14 critical features of mobile applications including ratings, reviews, sentiment analysis, install patterns, and behavioral anomalies. The system utilizes multiple machine learning algorithms to provide accurate fraud predictions with detailed probability analysis and visual insights.
Key Features and Capabilities
1. Multiple ML Algorithm Implementation
The system implements and compares 9 different machine learning algorithms to ensure optimal fraud detection performance. The Decision Tree model achieves perfect 100% accuracy across all metrics including precision, recall, F1-score, and ROC-AUC. Additional models include Random Forest (99.85% accuracy), XGBoost (99.80% accuracy), Logistic Regression, Support Vector Machine, K-Nearest Neighbors, Naive Bayes, Gradient Boosting, and Neural Networks.
2. Real-Time Fraud Prediction Engine
Users can input application data through an intuitive web interface and receive instant fraud probability analysis. The system processes 14 key features including app rating, number of reviews, app size, total installs, price, app type, sentiment analysis metrics, review-install ratios, rating anomalies, and categorical encodings to generate comprehensive fraud reports.
3. Advanced Sentiment Analysis Integration
The fraud detection system incorporates sophisticated sentiment analysis capabilities that evaluate average sentiment polarity, sentiment subjectivity, positive sentiment ratios, and sentiment-rating gaps. This multi-dimensional approach helps identify manipulated reviews and fake ratings commonly associated with fraudulent applications.
4. Interactive Data Visualizations
Powered by Chart.js library, the system provides beautiful interactive visualizations including model performance comparisons, feature importance analysis, fraud probability distributions, and real-time prediction results. These visual insights help users understand the detection process and make informed decisions.
5. Anomaly Detection Mechanisms
The system implements advanced anomaly detection algorithms that identify unusual patterns in app ratings, suspicious review-to-install ratios, and inconsistent sentiment-rating relationships. These mechanisms help catch sophisticated fraud attempts that traditional rule-based systems might miss.
6. Sample Data Testing Interface
For quick demonstrations and testing purposes, the application includes pre-loaded sample datasets representing both legitimate and fraudulent applications. Users can instantly test the system's capabilities without manually entering data.
7. Comprehensive Model Comparison Dashboard
The platform provides detailed performance metrics for all implemented algorithms, allowing researchers and developers to compare accuracy, precision, recall, F1-scores, and ROC-AUC values across different models. This transparency helps validate the system's reliability.
8. Modern Responsive User Interface
Built with modern web development technologies, the application features a responsive design that works seamlessly across desktop, tablet, and mobile devices. The gradient-based color scheme and intuitive navigation ensure excellent user experience.
Technical Architecture
FraudGuard utilizes Flask framework for backend operations, Scikit-learn and XGBoost for machine learning implementations, and Chart.js for frontend visualizations. The system processes data using Pandas and NumPy libraries, with model persistence handled through Joblib for efficient loading and prediction operations.
Real-World Applications
App Store Security Teams
Platform administrators can integrate this system to automatically screen new app submissions and identify potentially fraudulent applications before they reach users. This proactive approach protects the ecosystem integrity and user trust.
Mobile Security Researchers
Security professionals and researchers can utilize this tool to study fraud patterns, analyze malicious app behaviors, and develop improved detection methodologies. The comprehensive metrics and visualizations support academic research and security audits.
App Developers and Publishers
Legitimate developers can use this system to verify their applications meet quality standards and ensure their app metrics don't trigger fraud detection mechanisms. This helps maintain reputation and visibility on app stores.
Consumer Protection Organizations
Consumer advocacy groups can leverage this tool to identify and report fraudulent applications that pose risks to users through fake reviews, misleading ratings, or suspicious behavioral patterns.
Academic Research and Education
This project serves as an excellent educational resource for students learning machine learning, fraud detection, sentiment analysis, and web application development. The complete implementation provides hands-on experience with real-world ML applications.
Machine Learning Models Performance
The system's Decision Tree model achieves exceptional performance with 100% accuracy, precision, recall, F1-score, and ROC-AUC. The Random Forest ensemble method follows closely with 99.85% accuracy and 99.98% ROC-AUC. XGBoost gradient boosting algorithm delivers 99.80% accuracy with robust performance across all metrics. This multi-model approach ensures reliable fraud detection across diverse application types and fraud patterns.
Feature Analysis Capabilities
The system analyzes 14 critical features including app rating on 0-5 scale, total number of user reviews, application size in megabytes, cumulative install counts, pricing information, app type classification (free or paid), average sentiment polarity scores, sentiment subjectivity measurements, positive sentiment ratios, review-to-install ratios, rating anomaly indicators, sentiment-rating gap analysis, category code encodings, and content rating classifications. Each feature contributes to the comprehensive fraud assessment.
Technology Stack Benefits
Flask framework provides lightweight and flexible backend infrastructure for rapid development and deployment. Scikit-learn offers robust machine learning algorithms with excellent documentation and community support. XGBoost delivers state-of-the-art gradient boosting performance for complex pattern recognition. Chart.js enables beautiful interactive visualizations without heavy dependencies. Pandas and NumPy ensure efficient data processing and numerical computations.
System Scalability
The architecture supports easy scaling to handle increased prediction requests through load balancing and caching mechanisms. Model files are stored efficiently using Joblib serialization, enabling quick loading and minimal memory footprint. The system can be deployed on cloud platforms like AWS, Google Cloud, or Azure for production-grade performance.
Security and Privacy Considerations
The application processes only publicly available app store data and doesn't require access to sensitive user information. All predictions are performed server-side to protect model integrity. The system implements input validation and sanitization to prevent injection attacks and ensure secure operations, similar to best practices used in cybersecurity projects.
Future Enhancement Possibilities
Potential improvements include implementing deep learning models using TensorFlow or PyTorch, adding real-time data scraping from Google Play Store API, integrating automated reporting mechanisms, developing mobile application versions, implementing user feedback loops for continuous model improvement, adding multi-language support, and creating API endpoints for third-party integrations.
Perfect for Final Year Projects
This comprehensive system demonstrates advanced concepts in machine learning, web development, data science, and software engineering. The project includes complete source code, trained models, detailed documentation, and professional UI/UX design. Students can customize and extend the system for their specific requirements while learning industry-standard practices in ML application development. For additional project ideas, explore our complete projects catalog.
Documentation and Support
Complete project documentation includes installation instructions, API references, model training procedures, feature engineering explanations, and deployment guidelines. The codebase follows best practices with clear comments, modular structure, and comprehensive README files for easy understanding and modification. If you need assistance with project setup, our team is here to help.
Extra Add-Ons Available – Elevate Your Project
Add any of these professional upgrades to save time and impress your evaluators.
Project Setup
We'll install and configure the project on your PC via remote session (Google Meet, Zoom, or AnyDesk).
Source Code Explanation
1-hour live session to explain logic, flow, database design, and key features.
Want to know exactly how the setup works? Review our detailed step-by-step process before scheduling your session.
₹999
Custom Documents (College-Tailored)
- Custom Project Report: ₹1,200
- Custom Research Paper: ₹1000
- Custom PPT: ₹500
Fully customized to match your college format, guidelines, and submission standards.
Project Modification
Need feature changes, UI updates, or new features added?
Charges vary based on complexity.
We'll review your request and provide a clear quote before starting work.