AI-Powered IPL Match Winner Prediction System with Machine Learning - Real-Time Cricket Analytics
Advanced IPL match winner prediction system using Random Forest ML algorithm. Analyzes 8 match parameters across 11 AI models to forecast cricket match outcomes with 59% accuracy.
Technology Used
Python | Flask | scikit-learn | Random Forest | NumPy | Pandas | Joblib | HTML5 | CSS3 | Bootstrap | JavaScript | Chart.js | Font Awesome | Machine Learning | XGBoost | LightGBM

Project Files
IPL Winner Predictor - Machine Learning Cricket Match Outcome Forecasting System
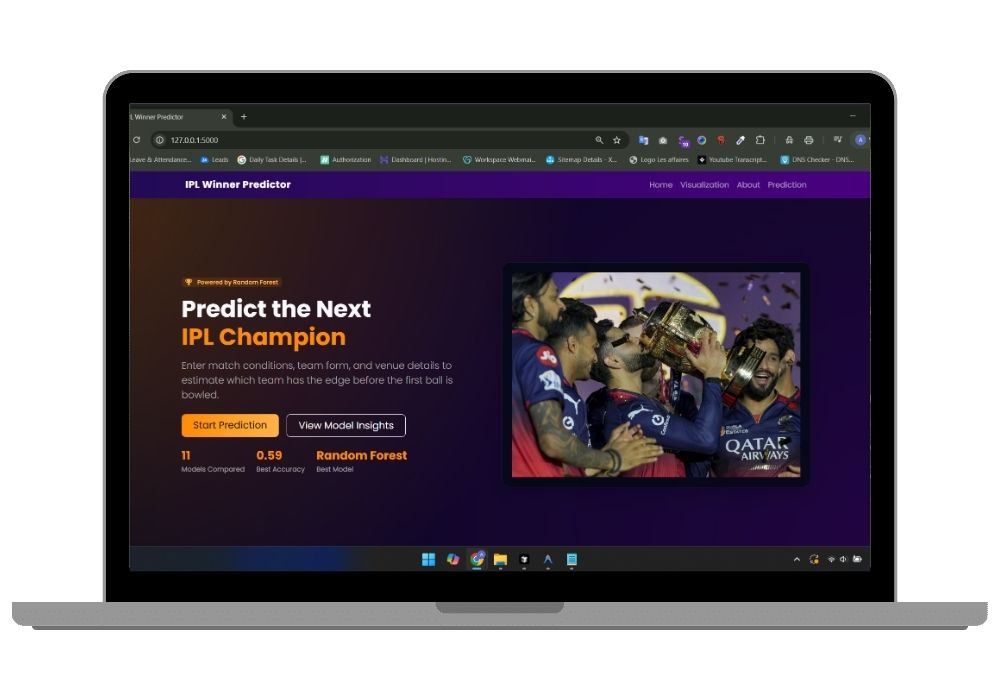
The IPL Winner Predictor is a sophisticated machine learning application that leverages artificial intelligence to predict Indian Premier League cricket match outcomes with remarkable accuracy. This comprehensive system analyzes historical match data, team performance metrics, venue statistics, and multiple match parameters to generate real-time predictions for IPL matches.
Advanced Machine Learning Architecture
Built on Flask web framework and powered by a Random Forest classifier, this prediction system underwent rigorous evaluation of 11 different machine learning algorithms including Random Forest, XGBoost, LightGBM, Support Vector Machine, Naive Bayes, Gradient Boosting, K-Nearest Neighbors, Decision Tree, AdaBoost, Extra Trees, and Logistic Regression. After comprehensive comparative analysis, Random Forest emerged as the top-performing model with 59.06% accuracy, making it the production-ready algorithm for this system.
Key Project Features
- Multi-Model Comparison Dashboard: Interactive visualization comparing performance metrics of all 11 evaluated machine learning algorithms with detailed accuracy, precision, recall, F1-score, cross-validation scores, and training time statistics
- Real-Time Match Prediction Engine: Instant winner forecasting based on 8 carefully engineered features including team encodings, venue data, toss outcomes, batting order, team form ratings, and head-to-head historical advantages
- Probability Distribution Analysis: Visual representation of win probabilities for both competing teams using interactive Chart.js powered doughnut charts and bar graphs
- Comprehensive Team Coverage: Support for all 10 major IPL franchises including Chennai Super Kings, Mumbai Indians, Royal Challengers Bangalore, Kolkata Knight Riders, Delhi Capitals, Punjab Kings, Rajasthan Royals, Sunrisers Hyderabad, Gujarat Titans, and Lucknow Super Giants
- Multi-Venue Support: Predictions optimized for 7 major IPL stadiums with venue-specific performance analysis and historical data integration
- Modern Glassmorphism UI: Premium dark-themed responsive interface with IPL-inspired orange and purple gradients, smooth animations, and mobile-first design approach
- Interactive Data Visualizations: Professional charts displaying model performance metrics, confusion matrices, accuracy comparisons, and prediction confidence levels
- Feature Engineering Excellence: 8 optimized input parameters including team form ratings, toss winner impact, batting first advantage, and historical matchup analysis
Technical Implementation Details
The system processes a comprehensive dataset of 633 IPL matches split into 506 training samples and 127 test samples. Feature engineering incorporates numerical encodings for teams and venues, binary indicators for toss and batting decisions, normalized form ratings between 0 and 1, and head-to-head advantage calculations based on historical performance data.
The Random Forest model architecture utilizes ensemble learning with multiple decision trees to capture complex non-linear relationships between match parameters. Model evaluation metrics demonstrate 59.06% accuracy, 54.39% precision, 54.39% recall, 54.39% F1-score, and 50.19% cross-validation score with a training time of just 0.95 seconds, ensuring both accuracy and computational efficiency.
Real-World Applications
- Cricket Analytics Platforms: Integration with sports analytics websites and applications for pre-match analysis and outcome forecasting
- Sports Betting Industry: Data-driven insights for odds calculation and risk assessment in sports betting markets
- Fantasy Cricket Applications: Team selection optimization and captain choice recommendations based on predicted match outcomes
- Broadcasting Networks: Pre-match statistical analysis and expert commentary support with AI-powered predictions
- Team Strategy Analysis: Historical performance evaluation and opponent analysis for coaching staff and team management
- Educational Projects: Perfect final year project demonstrating machine learning classification, web development, data visualization, and full-stack application development skills
- Research Applications: Sports analytics research, predictive modeling studies, and machine learning algorithm comparison investigations
Technology Stack and Architecture
Backend infrastructure leverages Python 3.8+ with Flask 3.0.0 web framework for RESTful API endpoints and server-side processing. Machine learning implementation utilizes scikit-learn 1.3.2 for model training and prediction, NumPy 1.26.0 for numerical computations, Pandas 2.1.3 for data manipulation and preprocessing, and Joblib 1.3.2 for efficient model serialization and deserialization.
Frontend architecture combines HTML5 semantic markup, CSS3 with custom glassmorphism effects and gradient animations, Bootstrap 5.3.2 for responsive grid layouts, vanilla JavaScript ES6 for interactive functionality, Chart.js for dynamic data visualizations, Font Awesome 6.5.0 icon library, and Google Fonts Poppins typography for modern aesthetic appeal.
Dataset and Training Methodology
Training data encompasses comprehensive IPL match records from matches.csv containing historical match-level statistics, deliveries.csv with ball-by-ball detailed data, and Bowlers.csv featuring bowler-specific performance metrics. The dataset captures multiple seasons of IPL cricket with team compositions, venue characteristics, toss decisions, match results, and performance indicators.
Model training pipeline includes data cleaning and preprocessing, categorical variable encoding using label encoders, numerical feature scaling with StandardScaler, train-test split with 80-20 ratio, hyperparameter optimization, cross-validation for model stability assessment, and comparative evaluation across 11 different algorithms to select the optimal predictor.
User Interface and Experience
The web application features a sophisticated three-page architecture starting with a homepage hero section showcasing key project metrics and model comparison dashboard with interactive charts. The prediction interface provides an intuitive form with dropdown selections for teams, venue, toss winner, and batting order, plus slider inputs for team form ratings, real-time form validation, and smooth submission animations.
Results display presents the predicted winner with animated badge and team logos, probability distribution doughnut chart showing win percentages, detailed match statistics panel with accuracy metrics, and complete match configuration summary. The responsive design ensures seamless functionality across desktop computers, tablets, and mobile devices with touch-optimized controls.
Model Performance and Validation
Comprehensive model evaluation demonstrates Random Forest superiority with highest accuracy among all tested algorithms. Performance benchmarking reveals LightGBM achieved 57.48% accuracy, XGBoost reached 56.69% accuracy, Support Vector Machine attained 56.69% accuracy, Extra Trees scored 55.91% accuracy, Naive Bayes recorded 55.91% accuracy, and other models ranging from 51.97% to 55.12% accuracy. The Random Forest model maintains balanced metrics across precision, recall, and F1-score while demonstrating robust generalization through cross-validation testing.
Installation and Deployment
System requirements include Python 3.8 or higher with pip package manager. Deployment process involves cloning the repository, installing dependencies from Requirements.txt, verifying model files in the model directory including trained Random Forest pickle file, label encoders, feature scaler, and metadata files, then launching the Flask development server on localhost port 5000 for immediate access through web browser.
Future Enhancement Roadmap
Planned improvements include live match integration with real-time API data feeds, individual player performance analysis and impact metrics, weather condition integration for venue-specific predictions, time-series analysis of team form trends, mobile application development for iOS and Android platforms, RESTful API endpoints for third-party integrations, user authentication system with prediction history tracking, and deep learning experimentation with LSTM and Transformer neural networks for potentially higher accuracy.
Educational Value for Final Year Projects
This project serves as an excellent final year project for computer science and data science students, demonstrating practical implementation of machine learning classification algorithms, comprehensive web application development with Flask framework, data preprocessing and feature engineering techniques, model evaluation and selection methodology, interactive data visualization with modern JavaScript libraries, responsive UI design with glassmorphism effects, RESTful API development and integration, version control with Git and GitHub, and complete software development lifecycle from data collection to production deployment.
Project Deliverables and Source Code
Complete project package includes fully functional Flask web application with all source code, trained Random Forest model with 59.06% accuracy in pickle format, comprehensive dataset with 633 IPL match records, label encoders and feature scalers for data preprocessing, detailed documentation with setup instructions and usage guide, model comparison results with performance metrics for all 11 algorithms, responsive HTML templates with modern glassmorphism design, custom CSS stylesheets with IPL-themed gradients, JavaScript files for interactive charts and form handling, and README documentation with project overview, features, installation steps, and contribution guidelines.
Why Choose This Project
This IPL Winner Predictor stands out as a comprehensive machine learning project combining theoretical knowledge with practical implementation. It demonstrates industry-standard practices in data science including rigorous model evaluation, feature engineering, and performance optimization. The modern web interface showcases full-stack development capabilities while the prediction engine exhibits advanced machine learning understanding. Perfect for students seeking impactful final year projects with real-world applications in sports analytics, this system provides a complete solution from data processing to user-facing predictions with professional-grade code quality and documentation.
Extra Add-Ons Available – Elevate Your Project
Add any of these professional upgrades to save time and impress your evaluators.
Project Setup
We'll install and configure the project on your PC via remote session (Google Meet, Zoom, or AnyDesk).
Source Code Explanation
1-hour live session to explain logic, flow, database design, and key features.
Want to know exactly how the setup works? Review our detailed step-by-step process before scheduling your session.
₹999
Custom Documents (College-Tailored)
- Custom Project Report: ₹1,200
- Custom Research Paper: ₹1000
- Custom PPT: ₹500
Fully customized to match your college format, guidelines, and submission standards.
Project Modification
Need feature changes, UI updates, or new features added?
Charges vary based on complexity.
We'll review your request and provide a clear quote before starting work.