SymptIQ — AI Disease Prediction Using Symptoms | Django Final Year Project
SymptIQ is an AI disease prediction web app built with Django and scikit-learn that analyzes symptoms to predict possible diseases with confidence scores and precautions.
Technology Used
Django 5.x | Python 3.10+ | scikit-learn 1.3+ | pandas 2.0+ | NumPy 1.24+ | joblib 1.3+ | Matplotlib 3.7+ | Seaborn 0.12+ | Chart.js 4.4.0 | SQLite 3 | Jupyter Notebook 7+ | HTML5 | CSS3 | Vanilla JavaScript | Font Awesome 6.5 | Google Fonts

Project Files
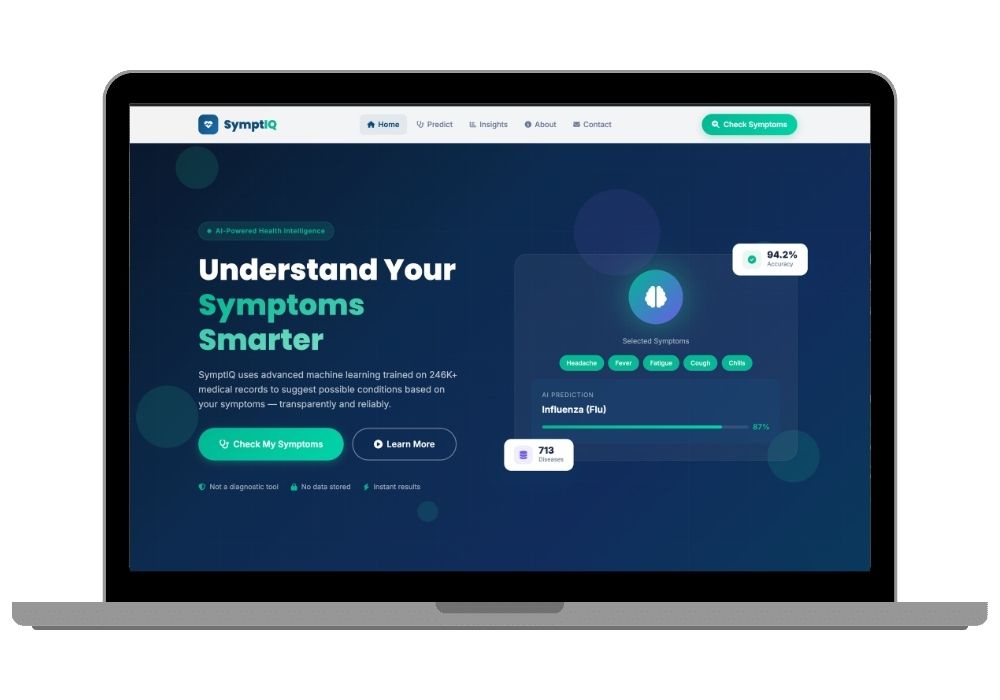
SymptIQ — AI Disease Prediction Using Symptoms
SymptIQ is a full-stack AI-powered disease prediction web application built with Django 5 and scikit-learn. It enables users to select symptoms from a comprehensive library of 377 binary clinical features, runs them through a machine learning model trained on 246,945 real-world medical records, and returns the top probable diseases with confidence scores, detailed descriptions, and recommended precautions. SymptIQ is one of the most technically advanced and practically relevant AI final year projects available on the CodeAj Marketplace, designed to meet the evaluation criteria of computer science and information technology final year submissions at the undergraduate and postgraduate level.
Whether you are looking for a ready-made Python final year project with source code or a complete academic deliverable including a pre-built project report, SymptIQ is a production-quality solution that demonstrates your command of machine learning, web development, REST API design, and data visualisation.
Medical Disclaimer: SymptIQ is a decision-support tool intended for academic and educational purposes only. It is not a diagnostic system. Always consult a licensed healthcare professional for any medical concerns.
Key Features of SymptIQ
Intelligent Symptom Checker
SymptIQ provides a beautifully designed symptom selection interface that organises all 377 symptoms across 10 body-system categories including General, Respiratory, Digestive, Neurological, Cardiovascular, Musculoskeletal, Skin, Mental Health, Urinary, and Other. Users can search for symptoms by name, filter by category using tab navigation, and select any combination using chip-style interactive elements. This makes the symptom input process fast, intuitive, and accurate.
AI-Powered Disease Prediction Engine
At the core of SymptIQ is a machine learning pipeline trained on 246,945 clinical records covering 713 distinct disease classes. Three classification models are evaluated during training — Naive Bayes, Logistic Regression, and Random Forest — and the best-performing model is automatically saved and loaded at runtime via a singleton DiseasePredictor class. For every prediction, SymptIQ returns the top 5 most probable diseases with confidence percentages above 1%, each enriched with a detailed description and a list of precautionary measures sourced from the disease information database.
Interactive Data Visualisations
The Data Insights page features five interactive Chart.js charts rendered in the browser. These include a horizontal bar chart of top disease distributions, a grouped bar chart comparing model performance metrics (accuracy, precision, recall, F1 score), a vertical bar chart of the top 20 most frequent symptoms, a 5-fold cross-validation accuracy chart, and a multi-model radar chart for holistic performance comparison. These visualisations provide strong academic depth and make SymptIQ stand out among standard final year projects.
Prediction Logging and Admin Panel
Every prediction made through the web interface is automatically logged to the SQLite database using the PredictionLog Django model, capturing the selected symptoms, predicted disease, confidence score, and timestamp. The Django admin panel provides full CRUD access to both prediction logs and contact form submissions, making SymptIQ suitable for demonstration to college faculty and project evaluators.
REST API for Programmatic Access
SymptIQ exposes three unauthenticated JSON REST API endpoints. The POST /api/predict/ endpoint accepts a list of symptom strings and returns structured disease predictions. The GET /api/symptoms/ endpoint supports partial keyword search across the full symptom list. The GET /api/chart-data/ endpoint serves chart data by type for disease distribution, symptom frequency, model performance, and daily prediction trends. These APIs allow frontend developers to integrate SymptIQ predictions into other applications or mobile interfaces.
Responsive and Accessible User Interface
SymptIQ's frontend is built with custom CSS using CSS custom properties (variables), Inter and Poppins Google Fonts, Font Awesome 6.5 icons, and smooth CSS animations. The layout is fully responsive across mobile, tablet, and desktop screen sizes. The UI includes an animated statistics counter on the home page, a tabbed symptom category selector, search-as-you-type symptom filtering, and a results page that cleanly presents disease confidence scores alongside structured precaution lists.
Machine Learning Models and Training Results
The SymptIQ training pipeline is fully documented in a Jupyter Notebook located at training/model_training.ipynb. The notebook loads the primary dataset, applies label encoding for 713 disease classes, splits data into 80% training and 20% testing sets, trains three classifiers, and evaluates each using accuracy, precision, recall, and F1 score metrics. A standalone train.py script is also included for users who prefer a command-line training approach.
The training results recorded in training_summary.json are as follows. Naive Bayes achieved 86.58% accuracy with an F1 score of 86.89%. Logistic Regression achieved 86.71% accuracy with an F1 score of 86.71%. Random Forest achieved 53.93% accuracy on the full 713-class problem, though it returned the highest precision at 76.18%. The best model by test accuracy is automatically selected and saved as best_model.pkl for use at runtime. Cross-validation mean accuracy across 5 folds was 54.69% with a standard deviation of 1.28%, demonstrating consistent generalisation on an extremely wide multi-class classification problem.
All trained model artefacts — including the serialised classifier, symptom feature list, label encoder, and disease information dictionary — are stored in the ml_models/ directory and loaded once at server startup through the DiseasePredictor singleton pattern, ensuring low latency for real-time predictions.
Real-World Applications of SymptIQ
Preliminary Health Screening Tool
SymptIQ can function as an accessible first-pass health screening tool in areas with limited access to healthcare professionals. By allowing users to identify possible conditions based on their symptoms, it supports informed decisions about whether to seek further medical consultation.
Hospital and Clinic Decision Support
Healthcare organisations can integrate SymptIQ's REST API into patient intake workflows. When a patient logs their symptoms at a kiosk or via a mobile app, the AI engine can immediately surface the most likely conditions for the attending physician's review, reducing time-to-diagnosis and improving triage efficiency.
Medical Education and Research
Medical students and researchers can use SymptIQ as a dataset exploration and model benchmarking platform. The interactive visualisation page provides instant insight into disease prevalence, symptom frequency distributions, and classifier performance trade-offs — all valuable educational content in a clinical machine learning context.
Academic Final Year Project Submission
SymptIQ is specifically designed for use as a final year project submission at the undergraduate and postgraduate level. It covers all standard evaluation criteria including problem statement, dataset description, algorithm comparison, REST API design, database integration, admin panel, and a complete responsive web interface. The accompanying pre-built project report and source code explanation service from CodeAj Marketplace make it easy to prepare for your viva and final submission.
Telehealth and Remote Patient Monitoring
The SymptIQ REST API can be embedded into telehealth platforms to provide automated symptom triage before a live consultation begins. By capturing and pre-analysing patient symptoms, the system reduces the cognitive load on healthcare providers and ensures consultations are more focused and productive.
Dataset Overview
SymptIQ is trained on a structured clinical dataset stored in dataset/data.csv, containing 246,945 patient records. Each record encodes 377 binary symptom columns (0 for absent, 1 for present) alongside a disease label column covering 713 distinct disease classes. A secondary file, dataset/final_symptoms_to_disease.csv, provides a text-based symptom-to-disease mapping useful for exploratory data analysis and reference. This extensive dataset ensures that SymptIQ's predictions are grounded in clinically meaningful patterns rather than synthetic or limited training samples.
Project Structure
SymptIQ follows a clean, modular Django project structure. The predictor/ application contains all core logic including the ML engine singleton, Django models, views, URL patterns, admin registrations, and custom template tags. The symptiq/ package holds all project-level settings, WSGI/ASGI configuration, and the root URL configuration. Static assets including the custom CSS, JavaScript, and image files are organised under static/, while global Django templates are stored in templates/. The training pipeline lives in training/model_training.ipynb and all serialised model artefacts are stored in ml_models/ after training completes.
Add-On Services from CodeAj Marketplace
Purchasing SymptIQ from CodeAj Marketplace gives you access to the complete source code, a pre-built academic project report, and a range of optional add-on services designed to support your final year project submission from start to finish.
Idea Implementation — If you want a customised version of SymptIQ tailored to a specific medical domain, dataset, or additional feature set, the CodeAj team can build it for you as a fully custom project.
Project Setup and Source Code Explanation — A CodeAj developer will set up the project on your local machine, walk you through the full source code, and ensure you can confidently explain every component during your viva examination.
Custom Project Report, Research Paper, and PPT — Our academic writing team will prepare a high-quality project report, a structured research paper suitable for journal or conference submission, and a polished presentation slide deck tailored to your institution's requirements.
Browse all available services at CodeAj Marketplace or explore more AI and machine learning final year projects from our catalogue.
Extra Add-Ons Available – Elevate Your Project
Add any of these professional upgrades to save time and impress your evaluators.
Project Setup
We'll install and configure the project on your PC via remote session (Google Meet, Zoom, or AnyDesk).
Source Code Explanation
1-hour live session to explain logic, flow, database design, and key features.
Want to know exactly how the setup works? Review our detailed step-by-step process before scheduling your session.
₹1499
Custom Documents (College-Tailored)
- Custom Project Report: ₹1,200
- Custom Research Paper: ₹1000
- Custom PPT: ₹500
Fully customized to match your college format, guidelines, and submission standards.
Project Modification
Need feature changes, UI updates, or new features added?
Charges vary based on complexity.
We'll review your request and provide a clear quote before starting work.